OpenSprinkler › Forums › OpenSprinkler Unified Firmware › slowish and droppish network
- This topic has 36 replies, 6 voices, and was last updated 11 years ago by
tom.
-
AuthorPosts
-
May 13, 2015 at 6:44 pm #37649
catalinParticipantHi,
Today I have wired the solenoids to OS and installed & operated first zone from the mobile app (Android v 1.4.2) – awesome 🙂
But I can not help myself but complain about how cumbersome this remote controlling is for me. Firmware is 1.8.3, coming from a DIY kit, and it generally takes about 30s – 1 minute for a zone to manually come up after switching it on from the app. Quite often during the day (perhaps 10 times) I got network error and was unable to reconnect to the OS controller until a reboot or an ethernet cable re-plug. The app has drained 2 and 1/2 batteries today for the tests, and I have noticed that the “stop all valves” command generally works faster, taking on average 5 secs. Ping to my router is 500 – 600 ms steady over two minutes, my internet connection is stable too. What could it be ?Thanks!
May 13, 2015 at 6:48 pm #37650
SamerKeymasterIf you are using firmware 1.8.3 then can I recommended you update to the latest version, 2.1.4? A lot of network issues have been resolved over the many versions since 1.8.3. Furthermore, manual mode in 1.8.3 takes quite a few round trip HTTP calls to confirm things are actually turned on, which isn’t ideal and likely adding to the time it takes.
May 14, 2015 at 5:11 pm #37676
catalinParticipantAh,much better!
May 30, 2015 at 8:36 am #38049
catalinParticipantHi,
Much better than 1.8 no doubt, But it still ciuld use some improvements 🙂
– quite often it happens for OS to become inaccessible through web browser. I go to it physically and the display says “connecting”. It becomes available again after a manual reatart, but that beats the purpose of a network controllable amenity
– the watering times for each zone look to me rather based on current time than on actual start time. So, if a zone starts at 12:43 and is scheduled to water for 2 minutes, it only runs for 1 min and 17 secs.Hope these will get addressed, thanks!
May 30, 2015 at 10:14 am #38052
DaveCParticipantRe: network connection issue.
I’ve seen the same behavior with current HW and FW, but I have not found a way to reproduce it at will. When the OS gets into this state, in addition to the LCD showing “Connecting”, the mobile app will show “Network Error” much of the time.
Here’s some info about my environment and what I’ve seen:
OS: HW – 2.3, FW – 2.1.4, Mobile App – 1.4.2
Network environment: OS is on the same subnet as the PC (used for ping’ing) and the Mobile app. The OS is hardwired. The PC and App devices are wireless through a standalone AP that is connected to the same switch as the OS.
Ping data from a windows PC (192.168.1.113 below) shows that the connection is seen in 3 states over a short period of time. The results were reproduced with OS IP address assigned by DHCP reservation (192.168.1.32 below) and Static IP. ping data below.• ping – successful
• ping – Request timed out
• ping – Destination host unreachable
In windows if the ‘reply from’ address is the sender’s IP address, the unreachable message indicates that the arp request for the destination MAC failed which is why it showed unreachable vs timed out.Ping data:
C:\Users\Dave>time /T
08:38 AMC:\Users\Dave>ping 192.168.1.32
Pinging 192.168.1.32 with 32 bytes of data:
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.Ping statistics for 192.168.1.32:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),C:\Users\Dave>time /T
08:38 AMC:\Users\Dave>ping 192.168.1.32
Pinging 192.168.1.32 with 32 bytes of data:
Reply from 192.168.1.32: bytes=32 time=5ms TTL=64
Reply from 192.168.1.32: bytes=32 time=3ms TTL=64
Request timed out.
Request timed out.Ping statistics for 192.168.1.32:
Packets: Sent = 4, Received = 2, Lost = 2 (50% loss),
Approximate round trip times in milli-seconds:
Minimum = 3ms, Maximum = 5ms, Average = 4msC:\Users\Dave>time /T
08:39 AMC:\Users\Dave>ping 192.168.1.32
Pinging 192.168.1.32 with 32 bytes of data:
Request timed out.
Request timed out.
Reply from 192.168.1.32: bytes=32 time=9ms TTL=64
Reply from 192.168.1.32: bytes=32 time=3ms TTL=64Ping statistics for 192.168.1.32:
Packets: Sent = 4, Received = 2, Lost = 2 (50% loss),
Approximate round trip times in milli-seconds:
Minimum = 3ms, Maximum = 9ms, Average = 6msC:\Users\Dave>time /T
08:40 AMC:\Users\Dave>ping 192.168.1.32
Pinging 192.168.1.32 with 32 bytes of data:
Reply from 192.168.1.32: bytes=32 time=116ms TTL=64
Request timed out.
Request timed out.
Reply from 192.168.1.32: bytes=32 time=6ms TTL=64Ping statistics for 192.168.1.32:
Packets: Sent = 4, Received = 2, Lost = 2 (50% loss),
Approximate round trip times in milli-seconds:
Minimum = 6ms, Maximum = 116ms, Average = 61msC:\Users\Dave>time /T
08:41 AMC:\Users\Dave>ping 192.168.1.32
Pinging 192.168.1.32 with 32 bytes of data:
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.
Reply from 192.168.1.113: Destination host unreachable.Ping statistics for 192.168.1.32:
Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),May 30, 2015 at 6:18 pm #38060
DaveCParticipantMy OS in this state now. Don’t know what triggered it. I haven’t touched the device since the previous post this morning. I’m going to leave this way. Let me know if there is something you want me to look at or try.
May 31, 2015 at 12:56 pm #38066
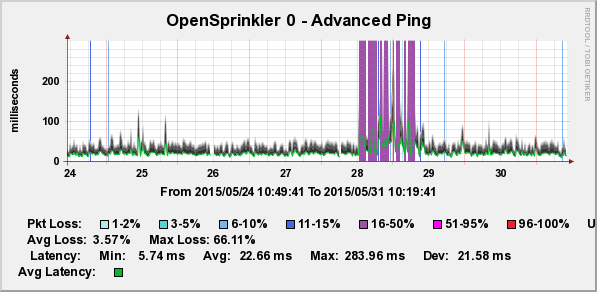
BrianParticipantI have also had this happen a few times with my HW v2.3, FW 2.1.4 OS. Pings start getting flakey, and most API calls timeout or fail, but some small percentage of the traffic still gets through though. It doesn’t appear to be related to the TP-Link wireless bridge, as rebooting the OS (via API call) immediately resolves the issue. I have attached a graph from my Cacti ping monitor for the OS before, during and after the issue appears.
Attachments:
June 1, 2015 at 1:22 am #38080
RayKeymasterIf anyone can run WireShark could you monitor the network traffic for a while? That may help find out the issue.
Because OpenSprinkler runs a microcontroller-based embedded server, it’s not as fast and robust as a Linux box. Especially if it’s performing other web tasks (like it periodically pings the router to see if it’s still connected), it can’t respond to incoming requests. That could explain why the ping sometimes works and sometimes doesn’t. Also, it periodically send requests to the cloud server, so that will temporarily block the incoming requests too. The firmware does check the connection and when it decides that it has lost connection it will re-start the Ethernet controller. In any case, all I am saying is that it’s a much weaker server than a Linux box.
June 1, 2015 at 1:27 am #38081
RayKeymasterBy the way, about the ‘Connecting…’ message, that means the controller cannot ping the router — the firmware is set to ping the router every few minutes to check if it’s still connected. If the ping requests fails several times in a roll, it will restart the Ethernet controller. So frequent ‘Connecting…’ means it’s not able to reach the router for some reason.
June 1, 2015 at 7:22 am #38083
catalinParticipantBy the way, about the ‘Connecting…’ message, that means the controller cannot ping the router — the firmware is set to ping the router every few minutes to check if it’s still connected. If the ping requests fails several times in a roll, it will restart the Ethernet controller. So frequent ‘Connecting…’ means it’s not able to reach the router for some reason.
Obviously, when ping fails there is a problem with connectivity. Attempting to immediately reconnect upon failed ping seems like not the best thing to do. It will and it does cause OS to hang. Some timer should be set in place, like, if connectivity not re-establishes in 1 minute, give up, free up TCP resources, reinit timer, re-attempt connection. Seems OS is not doing that since a manual restart clears the “connecting…” display immediately.
Thanks
June 1, 2015 at 8:07 am #38084
DaveCParticipantSince I can’t look at the LCD constantly, I don’t know how frequently the OS goes in/out of ‘Connecting…’ when it gets into this ‘state’. From a ping test perspective, I’m doing manual pings at random. Up until the afternoon of 5/30, I had no errors for about a week. Once I started seeing them, they persisted through 5/31 evening and each time I looked at the OS LCD it showed ‘Connecting…’. Now, 6/1 AM, pings seem to working regularly and the LCD display is its normal. I did nothing to the OS between last evening and this morning and there was no power outage.
I have very limited experience running Wireshark. If you give me some idea for what I should be looking for and a little help in setting up the Wireshark environment to capture that info, I’ll run it.
I understand that OS is not going to be a robust as a Linux box, but it does need to have reliable local network connectivity, not error free, but reliable. External connectivity is a different issue since it’s affected by other factors.
Looking at my failure environment this weekend: I don’t run irrigation programs on Sat or Sun afternoon, so the OS should have been fairly idle except for whatever it does during idle time.
• Ping the router. This should work a very high percentage of the time. It’s a hardwired connection from the OS to the router through a single switch. I could enable ICMP logging in my router but I’m not sure if this would provide useful info for this case.
• Requests to the cloud server. What server and why does it need to talk to it? I do not use automatic weather adjustment. Can I stop it from trying to talk externally? Tangentially… This brings up the question of JS for the browser. I’d be fine making this this local BUT, how often does the JS change? Opening the box to update it is OK once, but not on a regular basis. Could it be put on the SD card as part of an update so it was available locally?
• NTP. How often do you communicate with the NTP server?
• Other network activity?Let me know how I can help.
ThanksJune 1, 2015 at 3:29 pm #38093
BrianParticipantHi Ray,
I assume you want us to capture the network traffic I/O from the OS’s Ethernet port, and not a requesting client? This will require either adding a hub (not a switch) between the OS and the TP-Link/powerline adaptor or enabling port mirroring of the OS Ethernet port if you have a managed switch. You would then need to connect to an open port on the hub, or the mirror port on the switch using another machine with wireshark/tcpdump (with it’s NIC in promiscuous mode) to capture the traffic.
June 1, 2015 at 7:02 pm #38101
DaveCParticipantUpdate: Not complaining, just providing more data.
Since my previous post early this morning, my OS display is back to ‘Connecting…’ and getting ping errors when I ping it. I’ve not done anything to the OS today except ping it occasionally. It ran its schedule from midnight to 10:30 AM according to the log. It started failing again in the late morning. It’s now late afternoon. I’ve been watching the display for over 20mins and it has stayed in the Connecting…’ state. How long does it take to restart the controller? Could that logic be failing?I think I can monitor traffic from OS to my router via my router in some form. Since ‘Connecting…’ happens when a ping of the router fails, it seems like it would be interesting to see if OS is trying to ping it now and what it looks like in the normal state. I can’t promise anything since I’ve never tried to do this with the router before, but it seems like an easier experiment than Wireshark, and I’ll learn something new about my router.
June 1, 2015 at 9:06 pm #38104
DaveCParticipantI setup to log packets from the OS MAC address. I see a continuous stream that looks like the following where:
OS MAC address = 00:1e:c0:d7:2b:bd
192.168.1.32 is the OS IP address (via DHCP reservation)
These are DHCP requestsJun 1 19:40:16 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.32 DST=255.255.255.255 LEN=305 TOS=
0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=285
Jun 1 19:40:17 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=0.0.0.0 DST=255.255.255.255 LEN=293 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=273
Jun 1 19:40:17 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.32 DST=255.255.255.255 LEN=305 TOS=
0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=285
Jun 1 19:40:18 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=0.0.0.0 DST=255.255.255.255 LEN=293 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=273
Jun 1 19:40:18 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.32 DST=255.255.255.255 LEN=305 TOS=
0x00 PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=285
Jun 1 19:40:19 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=ff:ff:ff:ff:ff:ff:00:1e:c0:d7:2b:bd:08:00 SRC=0.0.0.0 DST=255.255.255.255 LEN=293 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=UDP SPT=68 DPT=67 LEN=273June 2, 2015 at 7:43 am #38109
DaveCParticipantUpdate: Last night I turned off the MAC address logger. This morning I looked and OS was responding to pings normally. I turned the MAC address logger back on and there was no activity for 15-20 minutes until 5:59AM. Then there was a burst for the same DHCP messages until 6:00. Now back to quiet. I’ll leave the logger on and watch for a little while this morning.
Misc info and other experiments if needed:
The DHCP lease time is 3 days. The router does not show lease info for static leases so I can’t say when the current lease is expected to expire from the router’s perspective.
Other experiments I could try:
Release the lease and see how the OS reacts.
Change the router to provide a regular DHCP address (with a shorter lease time) and observe.
Change the OS to a static IP and observe the behavior with the MAC logger. A week or so back while gathering info on this issue I set it to a static address and got into the same ‘Connecting…’ state.A little data is a dangerous thing…
With the data I have, the ping behavior fits.
The OS ‘loses’ its IP address and makes a DHCP request (SRC: 0.0.0.0). When it’s in that state the ‘host unreachable’ response to ping makes sense.
It gets its address (192.168.1.32). Now pings work.
But it doesn’t seem to know that it’s got an address and makes another DHCP request (SRC: 192.168.1.32). It then ‘loses’ it and starts over.
Given the amount of activity, the ping timeouts also make sense.
OK, I should leave the speculation to the experts. 🙂June 2, 2015 at 8:34 am #38113
DaveCParticipantUpdate: From 7:29 AM until 7:30 AM there was another DHCP burst.
June 2, 2015 at 10:40 am #38117
DaveCParticipantAnd one more update for the morning:
Another burst from 8:59 until 9:00. It appears to do this at 1.5 hour intervals for 1 minute until something else occurs and then the it goes on for a much longer time (yesterday afternoon and evening info).let me know if there is something else you want me to look at.
June 2, 2015 at 12:43 pm #38118
DaveCParticipantOK, I lied, another update:
At 10:29, 1.5 hrs after the last burst, the DHCP requests started again only this time they did NOT stop in 1 minute. I stopped logging at 11:27 because the rate can be as high a 6 requests per second.
If I don’t hear any back in ~30 mins, I’m going to restart the controller with a static IP address and watch its behavior.
June 2, 2015 at 2:46 pm #38123
DaveCParticipantI’ve restarted the OS with a static IP. I now see the OS pinging the router every 54s.
When I was logging traffic before, there were 0 pings, just DHCP request bursts.Jun 2 13:35:04 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=dc:9f:db:28:40:fc:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.80 DST=192.168.1.1 LEN=84 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=1360 SEQ=1
Jun 2 13:35:58 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=dc:9f:db:28:40:fc:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.80 DST=192.168.1.1 LEN=84 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=1360 SEQ=1
Jun 2 13:36:52 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=dc:9f:db:28:40:fc:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.80 DST=192.168.1.1 LEN=84 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=1360 SEQ=1
Jun 2 13:37:46 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=dc:9f:db:28:40:fc:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.80 DST=192.168.1.1 LEN=84 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=1360 SEQ=1
Jun 2 13:38:40 Rotary kernel: [LAN_Local-30-A]IN=eth1 OUT= MAC=dc:9f:db:28:40:fc:00:1e:c0:d7:2b:bd:08:00 SRC=192.168.1.80 DST=192.168.1.1 LEN=84 TOS=0x00
PREC=0x00 TTL=64 ID=0 DF PROTO=ICMP TYPE=8 CODE=0 ID=1360 SEQ=1June 2, 2015 at 7:35 pm #38133
RayKeymaster@catalin: the firmware uses increasingly longer timeout to perform re-connection. Specifically, if ping tests failed N times in a roll, it waits for 2^N minutes before re-connecting. There is no TCP resource to free or anything: it uses a statically allocated buffer, and there is no dynamically allocated memory.
June 2, 2015 at 7:53 pm #38137
RayKeymaster@DaveC: this is the first time I heard about the DHCP burst issue. I suspect it’s an issue with the EtherCard library that OpenSprinkler firmware is built on. I will use WireShark to monitor the web traffic and see if I can reproduce the issue.
Before we proceed, which firmware do you have? If you don’t have the latest firmware 2.1.4, I suggest that you upgrade to firmware 2.1.4 because it contains several Ethernet related bug fixes that may have fixed the issue. Even if your controller already shows firmware 2.1.4. I still recommend you to re-flash, because there was a silent update to 2.1.4 firmware a couple of weeks ago that wasn’t announced. In retrospect we should have numbered it 2.1.5 but the changes were too small to make it 2.1.5. Make sure you click on ‘Download Firmware’ before updating, so you can grab the latest files.
To be more specific, these are the most recent changes:
https://github.com/OpenSprinkler/OpenSprinklerGen2/commit/3f32a564e278f32ebfd3aae7efa15769f10e83f2
there is a bug with the way timeout is calculated and in some cases that could cause the controller to get stuck in the ‘Connecting…’ loop for a while. I should have brought this up earlier, but I am not 100% optimistic that this completely solves the issue. So I suggest updating the firmware and let me know if the issue still persists.June 2, 2015 at 8:33 pm #38141
DaveCParticipantI’ve had my OS for about 3 weeks. It came with 2.1.4 FW (All my version and environment info is near the start of this thread). Is there a way for me to tell if my FW is the newest, before I attempt my first FW update, and potentially screw i9t up?
I noticed the ‘Connecting…’ behavior with a few days when I was testing the device before replacing my current controller. I’ve put off that change over until this issue gets sorted out. I’ve been gathering data on it, but didn’t see the DHCP behavior until yesterday when I started logging what the OS was sending to the router.
A bug in timeout is one thing, but sending 4-6 DHCP requests per second for hours suggests a another issue.
Thanks
June 2, 2015 at 8:40 pm #38142
RayKeymasterThe last update as you can see:
https://github.com/OpenSprinkler/OpenSprinklerGen2/commit/3f32a564e278f32ebfd3aae7efa15769f10e83f2
is 12 days ago, which means most likely you have the previous version, so an update is highly recommended.When LCD shows ‘Connecting…’ it IS making a DHCP request and waiting for response to come back. So as I said, if for some reason, the bug was triggered and the controller gets stuck in the connecting loop, that can well explain the DHCP burst.
If you want to try, you can set the controller in static IP, which should bypass the DHCP burst.
June 2, 2015 at 9:08 pm #38144
DaveCParticipantAs noted above I am now running with a static IP. I have see the ‘Connecting…’ problem when running static in the past (farther back in this thread). I’m logging the OS to router traffic continuously now. I would not expect to see any DHCP requests when it fails while running static, but it will be interesting to see if there is any other unexpected messages. I’m expecting the regular pings to stop as they did in the previous test case.
I will update my FW.
June 2, 2015 at 9:17 pm #38145
RayKeymasterOK, sounds good. If you want to wait till next firmware update, you don’t have to update right now. Keeping it in static IP should avoid the DHCP burst as you already know.
-
AuthorPosts
- You must be logged in to reply to this topic.
OpenSprinkler › Forums › OpenSprinkler Unified Firmware › slowish and droppish network